Summary of Talk by Elvezio Ronchetti, Research Center for Statistics and GSEM, University of Geneva, Switzerland, presented at the 2022 March Meeting of the WA Branch of the SSA. This summary is written by Brenton R Clarke.
In introducing Elvezio I noted that he had published several important books on Robust Statistics and has visited La Trobe University, the Australian National University and Sydney University in the past. This time we hosted him virtually in Perth, Western Australia,
Elvezio outlined his talk with an introduction giving some motivation and then detailing three examples to illustrate the advantages of robust methods. He then outlined the infinitesimal approach based on what is known as the influence function and then related that to M-estimators known for their usefulness since they often include maximum likelihood estimators as a special case. Elvezio alluded to optimal robust estimators and then concluded with reference to new papers on penalization methods and machine learning
In his introduction he gave a summarizing slide to say that Robust Statistics
- deals with deviations from ideal models and their dangers for corresponding inference procedures.
- the primary goal is the development of procedures which are still reliable and reasonably efficient under small deviations from the model, i.e. when the underlying distribution lies in a neighbourhood of the assumed model.
Robust statistics is an extension of parametric statistics, taking into account that parametric models are at best only approximations to reality.
Elvezio asserted that Robust Statistics was about stability theory for statistics just as in other fields such as differential equations stability theory is exemplified by Lyapunov Theory, and similarly stability of mechanical structures is studied in engineering. In numerical analysis the computation of

is considered stable on the left hand side but not so on the right (I was surprised by this as usually we get students in first year classes to use the formula on the right to reduce the risk of miscalculation due to punching in a wrong number, but obviously the computer is more efficient when there are many large numbers in terms of reducing rounding errors and also not going out of bounds if you use the formula on the left.)
The basic premise in studying stability is that models are only approximations to reality, which is a basic tenet of science. Elvezio noted John Tukey’s discussion showing the dramatic loss of efficiency of optimal location procedures in the presence of small deviations and also in his first example illustrated the classical ‘dispute’ of Eddington and Fisher as to whether one should use the mean absolute deviation or the standard deviation based on efficiency in very small contaminated neighbourhoods of the normal model. (Personally, these studies were taught to me by Noel Cressie at Flinders University during my honours year when Noel was fresh out of doing a PhD at Princeton. I am forever grateful)
Example 2 considered the robustness of the Wilcoxon test in comparison to the two-sample t-test illustrated on 2 samples taken from normal distributions and allowing on sample point to vary. This illustrated that while the t-test is known to have robustness of validity it does not possess robustness of efficiency. It is noted the Wilcoxon test has robustness of validity, but as a nonparametric test loses power in small deviations from the assumed model.
Example 3 considered ARCH effects in financial time series given in Mancini, Ronchetti, Trojani (2005, JASA). The argument was that the ARCH parameter showed no significance when doing a classical Wald test implying acceptance of the homoscedasticity hypothesis whereas the robust test shows a highly significant . It is argued that because the estimation of the volatility by classical techniques is inflated, the potential ARCH structure is hidden by the presence of a few outlying observations.
Elvezio went on to discuss the functional approach to estimation where one, for example, writes their statistic as a function of the empirical distribution and more generally on the set of distributions so that one can set up the infinitesimal approach to estimation based on the influence function. In summary he explained that what was wanted were procedures that had bounded influence functions for which the reward was robustness. This is related to the theory of differentiability of statistical functionals for which my paper in Clarke (2000 PINSA) got a mention.
Elvezio pointed to M-estimators introduced in a famous 1964 paper by Huber in the Ann. Math. Statist., for which the empirical distribution is given by and the estimator can be written which is a solution of

From these subject to Fisher consistency the influence function at the model F is
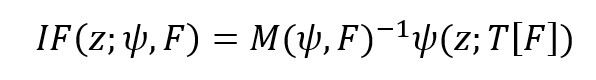
It is seen that bounding .jpg) leads to a bounded influence function. Elvezio pointed to eleven bookson robustness, to see how the field has progressed. I was pleased to see the most recent book listed was Clarke (2018) Robustness Theory and Application, John Wiley & Sons.
leads to a bounded influence function. Elvezio pointed to eleven bookson robustness, to see how the field has progressed. I was pleased to see the most recent book listed was Clarke (2018) Robustness Theory and Application, John Wiley & Sons.
In concluding his talk Elvezio canvassed penalization methods. He covered penalty methods for dealing with what is called sparsity and noted that estimating a regression parameter yields an M-estimator. In particular, the Huber estimator corresponds to the lasso penalty. Several references on the penalization literature were given with a statement that a popular approach to the Machine Learning literature is to enforce robustness in available algorithms.
Elvezio suggests we look for estimators with bounded influence functions. His approach would be to “huberize” the score function. Robustness is an issue in the big data world and there is an equivalence between robustness and penalization.
Brenton Clarke

 @StatSocAus
@StatSocAus